An Actionable Common Approach to Federal Enterprise Architecture
The recent “Common Approach to Federal Enterprise Architecture” (US Executive Office of the President, May 2 2012) is extremely timely and well-organized guidance for the Federal IT investment and deployment community, as useful for Federal Departments and Agencies as it is for their stakeholders and integration partners. The guidance not only helps IT Program Planners and Managers, but also informs and prepares constituents who may be the beneficiaries or otherwise impacted by the investment. The FEA Common Approach extends from and builds on the rapidly-maturing Federal Enterprise Architecture Framework (FEAF) and its associated artifacts and standards, already included to a large degree in the annual Federal Portfolio and Investment Management processes – for example the OMB’s Exhibit 300 (i.e. Business Case justification for IT investments).
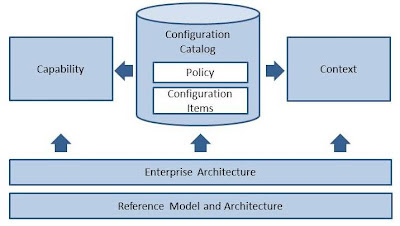
A very interesting element of this Approach includes the very necessary guidance for actually using an Enterprise Architecture (EA) and/or its collateral – good guidance for any organization charged with maintaining a broad portfolio of IT investments. The associated FEA Reference Models (i.e. the BRM, DRM, TRM, etc.) are very helpful frameworks for organizing, understanding, communicating and standardizing across agencies with respect to vocabularies, architecture patterns and technology standards. Determining when, how and to what level of detail to include these reference models in the typically long-running Federal IT acquisition cycles wasn’t always clear, however, particularly during the first interactions of a Program’s technical and functional leadership with the Mission owners and investment planners. This typically occurs as an agency begins the process of describing its strategy and business case for allocation of new Federal funding, reacting to things like new legislation or policy, real or anticipated mission challenges, or straightforward ROI opportunities (for example the introduction of new technologies that deliver significant cost-savings).
The early artifacts (i.e. Resource Allocation Plans, Acquisition Plans, Exhibit 300’s or other Business Case materials, etc.) of the intersection between Mission owners, IT and Program Managers are far easier to understand and discuss, when the overlay of an evolved, actionable Enterprise Architecture (such as the FEA) is applied. “Actionable” is the key word – too many Public Service entity EA’s (including the FEA) have for too long been used simply as a very highly-abstracted standards reference, duly maintained and nominally-enforced by an Enterprise or System Architect’s office.
Refreshing elements of this recent FEA Common Approach include one of the first Federally-documented acknowledgements of the “Solution Architect” (the “Problem-Solving” role). This role collaborates with the Enterprise, System and Business Architecture communities primarily on completing actual “EA Roadmap” documents. These are roadmaps grounded in real cost, technical and functional details that are fully aligned with both contextual expectations (for example the new “Digital Government Strategy” and its required roadmap deliverables – and the rapidly increasing complexities of today’s more portable and transparent IT solutions. We also expect some very critical synergies to develop in early IT investment cycles between this new breed of “Federal Enterprise Solution Architect” and the first waves of the newly-formal “Federal IT Program Manager” roles operating under more standardized “critical competency” expectations (including EA), likely already to be seriously influencing the quality annual CPIC (Capital Planning and Investment Control) processes.
Our Oracle Enterprise Strategy Team (EST) and associated Oracle Enterprise Architecture (OEA) practices are already engaged in promoting and leveraging the visibility of Enterprise Architecture as a key contributor to early IT investment validation, and we look forward in particular to seeing the real, citizen-centric benefits of this FEA Common Approach in particular surface across the entire Public Service CPIC domain – Federal, State, Local, Tribal and otherwise. Read more Enterprise Architecture blog posts for additional EA insight!