Link: http://feedproxy.google.com/~r/Soapbox/~3/muJnevntNPs/dark-data.html
From Architecture, Data and Intelligence
At @imperialcollege this week to hear Professor David Hand talk about his new book on Dark Data.
Some people define dark data as unanalysed data, data you have but are not able to use, and this is the definition that can be found on Wikipedia. The earliest reference I can find to dark data in this sense is a Gartner blogpost from 2012.
In a couple of talks I gave in 2015, I used the term Data Data in a much broader sense – to include the data you simply don’t have. My talks both included the following diagram.
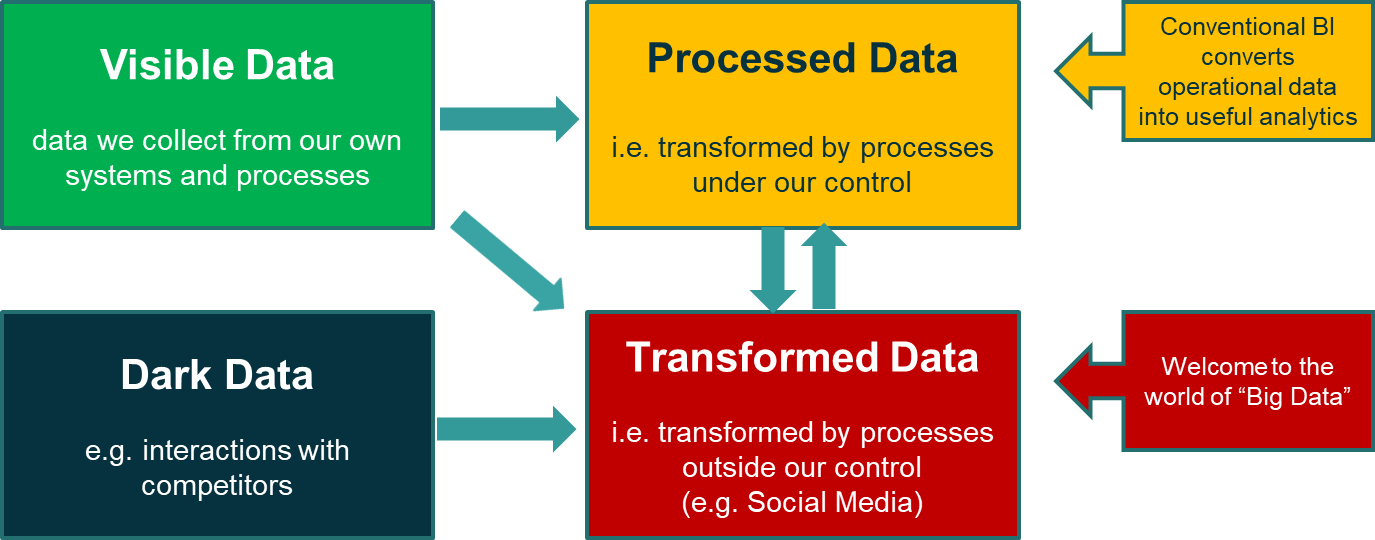
Here’s an example of this idea. A supermarket may know that I sometimes buy beer at the weekends. This information is derived from its own transaction data, identifying me through my use of a loyalty card. But what about the weekends when I don’t buy beer from that supermarket? Perhaps I am buying beer from a rival supermarket, or drinking beer at friends’ houses, or having a dry weekend. If they knew this, it might help them sell me more beer in future. Or sell me something else for those dry weekends.
Obviously the supermarket doesn’t have access to its competitors’ transaction data. But it does know when its competitors are doing special promotions on beer. And there may be some clues about my activity from social media or other sources.
The important thing to remember is that the supermarket rarely has a complete picture of the customer’s purchases, let alone what is going on elsewhere in the customer’s life. So it is trying to extract useful insights from incomplete data, enriched in any way possible by big data.
Professor Hand’s book is about data you don’t have – perhaps data you wish you had, or hoped to have, or thought you had, but nevertheless data you don’t have
. He argues that the missing data are at least as important as the data you do have
. So this is the same sense that I was using in 2015.
Hand describes and illustrates many different manifestations of dark data, and talks about a range of statistical techniques for drawing valid conclusions from incomplete data and for overcoming potential bias. He also talks about the possible benefits of dark data – for example, hiding some attributes to improve the quality and reliability of the attributes that are exposed. A good example of this would be double-blind testing in clinical trials, which involves hiding which subjects are receiving which treatment, because revealing this information might influence and distort the results.
Can big data solve the challenges posed by dark data? In my example, we might be able to extract some useful clues from big data. But although these clues might lead to new avenues to investigate, or hypotheses that could be tested further, the clues themselves may be unreliable indicators. The important thing is to be mindful of the limits of your visible data.
David J Hand, Dark Data: Why what you don’t know matters (Princeton 2020). See also his presentation at Imperial College, 10 February 2020 https://www.youtube.com/watch?v=R3IO5SDVmuk
Richard Veryard, Boundaryless Customer Engagement (Open Group, October 2015), Real-Time Personalization (Unicom December 2015)
Andrew White, Dark Data is like that furniture you have in that Dark Cupboard (Gartner, 11 July 2012)
Wikipedia: Dark Data
Related post: Big Data and Organizational Intelligence (November 2018), Dark Data and the US Election (November 2020)