Link: http://weblog.tetradian.com/2020/05/28/where-have-all-the-good-skills-gone/
[to the tune of “Where have all the flowers gone?”]Where have all the good skills gone?
Long time passing
Where have all the good skills gone?
Long time ago
Where have all the good skills gone?
Gone to robots every one
When will they ever learn?
When will they ever learn…
This one’s really a corollary or implication of the previous post – ‘On skills: 10, 100, 1000, 10000 hours‘ – on how long it takes to learn real skills.
We hear frequent complaints about skills shortages, in almost every industry. Talented, experienced people are hard to find, it seems. Yet few people seem to be considering the possibility that we’re actually creating that skills shortage by the way we design and ‘engineer’ our businesses. From a sidewise view, it seems likely that the skills shortage isn’t something that’s ‘just happened’, but is a direct consequence of the current fad for ‘re-engineering’ everything, converting every possible business process into automated form. ‘Lean and mean’ and the like will seem great ideas, in the short term especially – but without care, and awareness of the subtle longer-term impacts, they can easily kill the company. Not such a great idea, then…
There are ways to deal with this – but to do so needs a better understanding of skill – and especially of how skills develop, and where they come from.
The first key point is that not every process can be automated. If you read the sales-pitches of some of the proponents of business process re-engineering, for example, it might seem that every aspect of the business can be converted to automated web-services and the like. But the reality is that simply isn’t true: the percentage will vary from one industry to another, but the bald fact is that on average, less than a third of business activities are suitable for automation. The remainder are ‘barely repeatable processes’ that are not only unsuitable for automation, but require genuine skill to complete.
Which brings us to the second key point: any process which requires genuine skill can never be fully automated. The inverse of that statement is possibly more accurate: an automated process cannot implement the full range of skilled decision-making. Automation can do a subset – sometimes a very large subset – but it cannot do it all: which means that if we rely on automation alone, the business process will fail whenever the automated decision-making is not up to the task.
To understand why this is so, look at the SCAN model, also referenced in that previous post on skills. SCAN covers the whole scope of decision-making. Given an initially unknown context – which is what we have whenever we start a business process – we have four classic ways to resolve the ‘unknown’: rule-based, analytic, heuristics, principles. In effect, as in that “10, 100, 1000, 10000″ post, they’re a hierarchy of skill-levels, from minimal (rule-based) to extreme (principle-based):
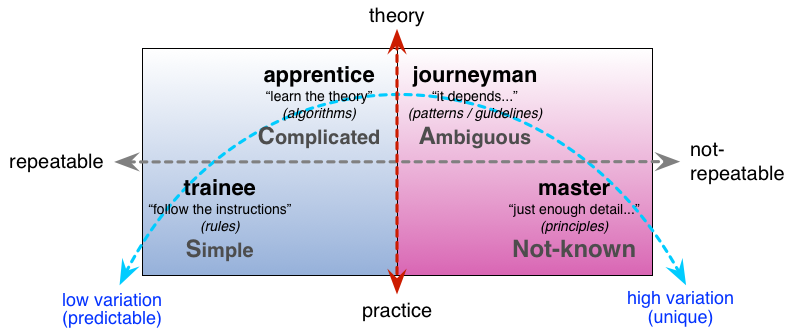
Most automation – especially in physical machines – is rule-based: the exact same decision-path is followed, every time, regardless of what else may be in play. IT-based systems can also handle varying levels of analytics, requiring more complicated or calculated decision-paths, and often at very high speed. But everything there is still dependent on the initial assumptions: and if those assumptions no longer hold – as they often don’t in true complexity, let alone in the subtle chaos of the real world – then automation on its own will again fail. Hence the need, in almost every conceivable business process, for ‘human in the loop’ escalation or intervention, to make the decisions that cannot or should not be made by machines alone.
But as machines and IT-systems take on more and more of the routine rule-based and analytic decisions – the ‘easily repeatable processes’, the ‘automatable’ aspects of business – a key side-effect is, almost by definition, that the skill-levels needed to resolve the ‘non-automatable’ decisions will increase. But because it seems so easy to automate some parts of processes, it’s easy to ignore the non-automatable decisions: at best, they get shoved to one side, tagged with the infamous label “Magic Happens Here”. And because the automatable parts of the process can be done ever faster with increasing compute-power and the like, the pile in the ‘too-hard basket’ just keeps growing and growing, until it chokes the process to death, or causes some kind of fatal collapse. Worse, the more simulated-skill we build into an automated system, the higher the skill-level needed to resolve each item which can’t be handled by the automated parts of the overall system. In short, the more we automate, the harder it becomes to resolve any real-world process.
To give a real example, consider sorting the mail. It all used to be done by hand, at the main sorting office and at the local branch post-offices. Sorting staff developed real skills at deciphering near-illegible scrawls; local delivery-staff used their local knowledge to resolve most of the mis-addressed mail. But manual processes like that are slow; so to handle large volumes, two key components were introduced: machines, to read the more easily-interpretable addresses; and post-codes, both to make it easier for the machines, and to pass more of the routing-decisions onto the person or system writing the initial mail-address.
The machines ‘succeed’ because they only have to make a subset of the decisions within the overall sorting process. Anything they can’t handle on their own is handballed to a human operator to resolve. But we now require two different skillsets in human mail-sorters: machine-operators, who can handle another subset of decisions at high speed, to keep pace with the machines; and the expert interpreters, who have somewhat more time to do the best they can with the really indecipherable scrawls. In SCAN terms, the machines do rule-based decisions (simple interpretation of printed post-codes) and analytics (algorithmic interpretation of handwriting); the operators tackle much of the complex domain (heuristic interpretation, plus decision to escalate to the experts); and the experts, who deal with the complex and chaotic domains.
But there’s a catch: how do those ‘humans in the loop’ learn the skills needed to do the job? By definition, they’re doing difficult work – too difficult for the machines to do their own. To put it the other way round, the machines do all of the easy work, and (usually) do it well: but that means that all the hard work is left to the humans. (That it often isn’t even acknowledged as skill is an interesting point in itself – a common cause of failures in classic Taylorist-style assembly-line process designs, for example.) But the way that humans learn skills is in a hierarchy of levels: first the rules, then the more complicated analytic versions of the rules, then the heuristic ‘exception that proves the rule’, and then finally a full almost intuitive grasp of the principles from which those apparent rules arise. If we try to skip any of those stages, everything falls apart: it’s possible to use principles straight off, for example, but without that firm foundation of knowing how and when why the rules exist, in order to ‘break the rules’, we can’t trust it in the real-world. Maybe in an emergency, perhaps, but not on a production-line – and it’s the latter that we’re concerned with here.
So people learn the skill by learning the rules, then the more complicated rules, and so on. The ‘10, 100, 1000, 10000 hours’ rule tells us roughly how long it’ll take: a trainee will take a day to get started; at least a couple of weeks to make some degree of sense of what’s going on; and six months or so to even begin to be able to make contextual heuristic decisions that are better than the built-in ‘best-practices’ of the machines.

Yet if we don’t allow them that time, and don’t give them access to the decisions that are embedded within the machines, there’s no way that they can learn:
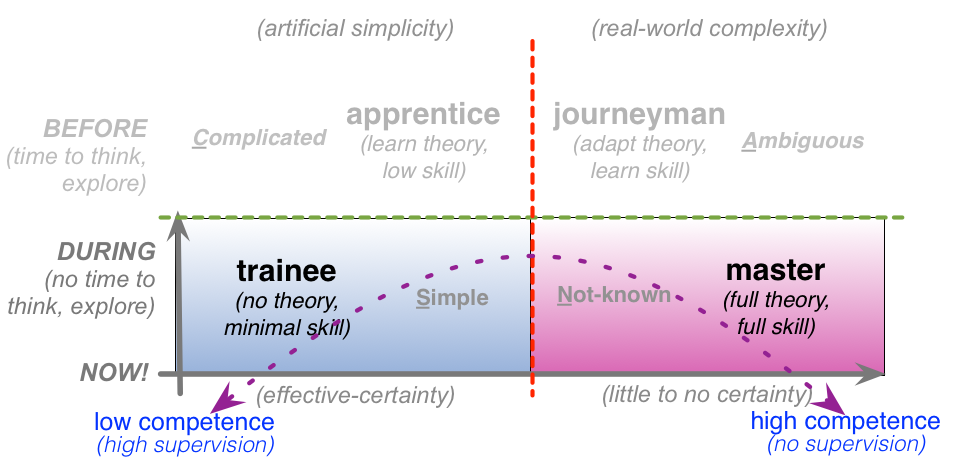
On top of that, if we don’t make it safe to learn – if there isn’t a ‘safe-fail’ practice-space in which people can safely learn from their mistakes – there’ll be a serious disincentive to learn the needed skills. And business-specific skills can only be learnt on the job – they can’t be hired in from elsewhere. All of which can add up to serious business problems, especially in the longer term.
So what to do about it? The simplest way, perhaps, is to focus on questions such as these:
What decisions need to be made within each aspect of the business? What skills are needed to underpin each of those decisions? What level of skill – rule-based, analytic, heuristic, principle-based – is needed in each case?
What guides each of those decisions? Are the rules imposed from outside – such as via regulations, industry standards or social expectations – or from the business’ own principles, policies, procedures and work-instructions?
By what means are decisions escalated? Rules are always an abstraction of the real world: there’ll always be situations where they won’t work. The same applies to analytics, and to heuristics: at the end – as typified in so many business stories – everything can depend on principles. But how is each decision escalated from one level to the next? What skills are needed to understand how and when and why to escalate in each case? What mechanisms are used to signal such escalation, and pass the decisions up and down the skills-tree?
If decisions are embedded within automated systems, how may people learn the means by which those decisions are made? Machines and IT-systems can handle rule-based and algorithmic decisions: but people who need to take over those decisions in business-continuity and disaster-recovery need to know what those decisions are, and how to make those decisions themselves. These first- and second-order skills are also the foundation for higher-order escalated decisions: we need to know what the rules are, and why they are, before we can be trusted to break them. We also need to people to be able to take over when the machines fail, or simply when they’re overloaded – as occurs every Christmas in the mail-sorting context, for example. This is one key reason why disaster-recovery planning is a good place for trainees to start to learn the business – and business-continuity a good place to put that knowledge into practice.
What incentives exist for people to learn the skills the business needs? For that matter, how can we make it safe for people to learn? Most people learn by learning from their mistakes, so if it’s not safe to make mistakes, no-one will dare to risk learning anything. If people are to learn the higher-order skills, they need safe ‘practice-space’ where their inevitable mistakes will have minimal impact on the business and its clients; and they need time to learn, too. All these can work if the right incentives are in place – or, perhaps more important, if there are also no serious disincentives to learning.
Where have all the good skills gone? Lost in automation every one, if we’re not careful. But sidewise questions such as those above can help to retrieve the skills that we need – and keep improving quality and value throughout every aspect of the business.
(Note: This is an updated version of the post ‘Where have all the good skills gone?’, first published on 27 July 2009 on my now-defunct Sidewise blog.)